
Subagents with MCP
Subagents with MCP
A big gripe people have with MCP is the always-on context hit. For Sentry in a basic form, this is ~14,000 tokens. That’s not an enormous amount, but its also not nothing. People have been trying to come up with inventive solutions to work around it, and many have sworn off MCP for CLIs for this reason. We’ve also seen proliferation of poorly designed MCPs that make Sentry’s not insignificant 14,000 tokens look like nothing.
What if we could eliminate the token cost of MCP and at the same time enable smarter agents?
If you’re not familiar with MCP, or how it works, here’s the quick explainer for you: its a way to build a plugin that provides a set of tools, and (importantly) metadata around those tools, and expose them to agents that you otherwise don’t control. This gives them new capabilities beyond what the authors themselves designed.
I shipped an experiment in Sentry’s MCP that I’m calling Agent Mode. It wraps up the MCP provider into an embedded agent (commonly called a subagent) and instead of exposing the composable tool suite, it exposes a single use_sentry tool. That tool consumes ~720 tokens in Claude Code as of the time of writing - a 95% reduction. Let’s talk a bit about how thats implemented, what’s amazing about it, and why it also has its own problems.
First, to understand what we’re exposing you have to understand the MCP that Sentry is exposing. It’s designed to be used with coding agents like Cursor and Claude Code. Its our initial pass at exposing Sentry context to those agents to make it really fast to debug issues. For example, a common flow for me is dropping a Sentry URL into the agent and asking it to work through it. The combination of Sentry, the agent, and in particular the selective context our MCP epxoses makes it really effective. It also is far more reliable than simply copy pasting a stack trace, and that compounds when running in parallel with our remote debugging agent (Seer). All in all, we’re able to package up a bunch of capabilities and selectively expose the most relevant information to your agent.
Its not that simple though, because while that’s only a couple of tools to achieve the above, there’s a handful of helper tools. Some of them “make conversation work” - they allow you to prompt poorly and will aid in looking up details about your organizations and projects. Some enable other workflows like searching your data, or answering analytical questions using it, and even looking up documentation in case you’re instrumenting Sentry right now. Suffice to say this is where the problem comes in from token consumption: a lot of tools that are always-on and not always needed.
Our first pass to work through this was to enable scope selection in the OAuth flow. This had the benefit of also allowing you to restrict what the agent had access to:
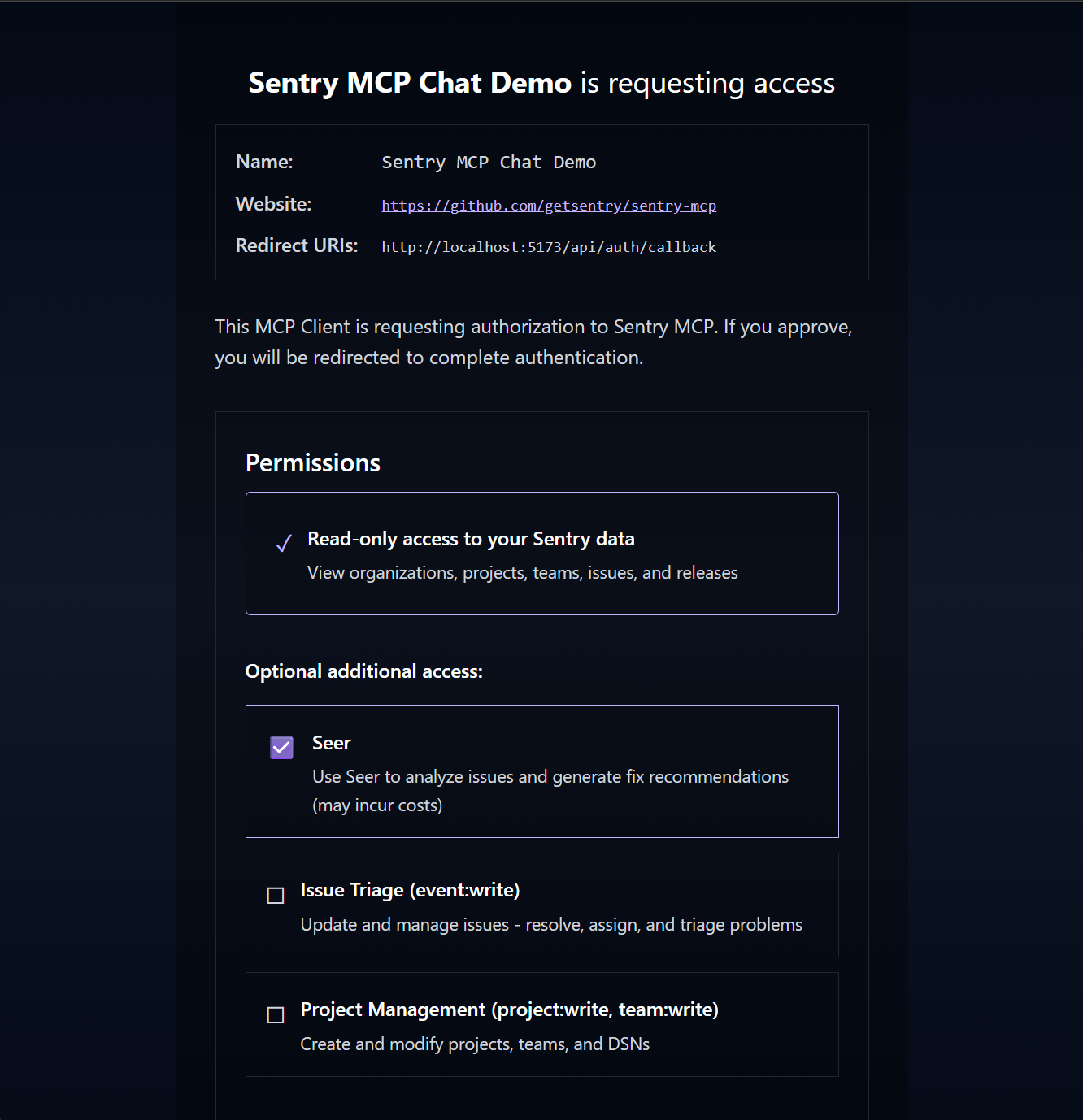
This helped quite a lot, but that benchmark number (14,000 tokens) is with only the default selections. Clearly not enough. You can optimize the tool metadata here and there, but at the same time a lot of the power comes from being able to influence the third-party agent using tool metadata. For example, helping it understand when it should use a specific tool, or how it should use it, that all has to live in the always-on metadata.
We had been experimenting with embedded agents inside of the MCP (our search tools use them), and it gave us the idea to push the entire thing behind a custom agent. We’d insert a new agent between Claude Code and the MCP itself. To our surprise this was fairly easy with the TypeScript SDK, as it provides an in-memory protocol binding.
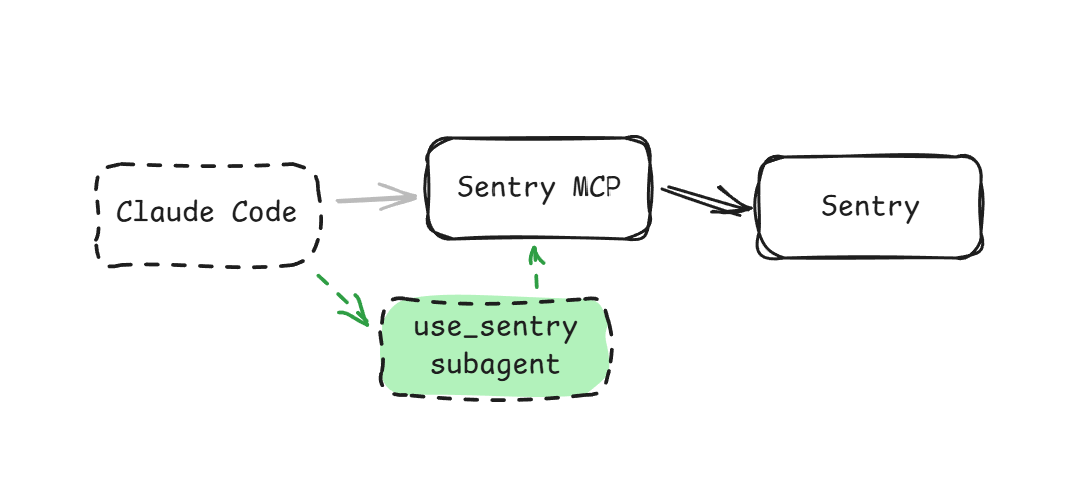
Here’s a snippet from our use_sentry tool, which bundles up the pre-existing MCP tools, their scoping and constraints, and everything else we had already built:
import { InMemoryTransport } from "@modelcontextprotocol/sdk/inMemory.js";
import { experimental_createMCPClient } from "ai";
import { useSentryAgent } from "./agent";
// ...
// Create linked pair of in-memory transports for client-server communication
const [clientTransport, serverTransport] = InMemoryTransport.createLinkedPair();
// Create MCP client with the other end of the transport
const mcpClient = await experimental_createMCPClient({
name: "mcp.sentry.dev (use-sentry)",
transport: clientTransport,
});
// Get tools from MCP server (returns Vercel AI SDK compatible tools)
const mcpTools = await mcpClient.tools();
// Call the embedded agent with MCP tools and the user's request
const agentResult = await useSentryAgent({
// XXX: request is the user's input
request: params.request,
tools: mcpTools,
});There’s a bit more to it than that, but its surprisingly easy! The agent is nothing special at all, but we did find ourselves having to tweak the use_sentry tool description and I would not say we’ve nailed the ideal experience yet. In particular how it behaves with URLs was the first gotcha we encountered - not something that existed with tool selection previously.
Use Sentry's MCP Agent to answer questions related to Sentry (sentry.io).
You should pass the entirety of the user's prompt to the agent. Do not interpret the prompt in any way. Just pass it directly to the agent.",We’ve found itll often intercept things like GitHub URLs to the Sentry repo, will fail, and then do what you’d expect. Not ideal, but not the end of the world. This can likely be solved with tuning the description as its effectively a prompt.
The agent itself is even similar - again not scientific here, pure vibes - and just tries to keep it tool focused. What’s important here is that you can actually put a lot of influence in how it understands parameters, which would allow you to remove a lot of coercion that otherwise needs to exist in your tool or parameter definitions:
You are an agent responsible for assisting users on accessing information from Sentry (sentry.io) via MCP tools.
ALWAYS evaluate which tools are the most appropriate to use based on the user's prompt. You ALWAYS use tools to answer questions. Evaluating the tool descriptions and parameters thoroughly to answer the user's prompt.
The user may include various parameters to pass to those tools in their prompt. You MUST treat URLs as parameters for tool calls, as well as recognizing <organizationSlug>/<projectSlug> notation.
You MUST return tool results directly without interpreting them.Thats it! We enabled this via a query parameter (?agent=1) on the MCP server.
Except its not all sunshine and rainbows. There’s a few minor issues we immediately saw, and one unfortunately major concern.
The minor issues are mosty around the lack of composability of the tools (its all deferred to the subagent), some directional prompting that isnt as ideal, but the worst version of that is its less organic. I will often now need to more directly tell it to use Sentry, but that’s probably totally fine and might be preferred in some places.
An issue that has more consequence unfortuntaely is harder to work around… response times doubled for typical tool use. This wasn’t unexpected, but the impact was more than I had wanted. We’re calling GPT-5 under the hood which has an obvious cost to it that wasn’t there before, but most of the cost that we care about is the response time. You can see the results from a simple benchmark below:
➜ ~/s/sentry-mcp (main) ✔ ./benchmark-agent.sh
==========================================
MCP Agent Performance Benchmark
==========================================
Query: what organizations do I have access to?
Iterations: 10
Running direct mode tests...
Run 1/10... 10.876837870s
Run 2/10... 17.804097437s
Run 3/10... 8.637378803s
Run 4/10... 8.992257018s
Run 5/10... 10.862649786s
Run 6/10... 16.975990972s
Run 7/10... 10.566292161s
Run 8/10... 9.204778077s
Run 9/10... 10.518423250s
Run 10/10... 8.508621442s
Running agent mode tests...
Run 1/10... 19.436035538s
Run 2/10... 17.623815548s
Run 3/10... 31.055687961s
Run 4/10... 22.744690925s
Run 5/10... 22.402612281s
Run 6/10... 20.129163521s
Run 7/10... 19.148300195s
Run 8/10... 26.634274552s
Run 9/10... 39.572749400s
Run 10/10... 19.353856522s
==========================================
Results
==========================================
Direct Mode:
Min: 8.508621442s
Max: 17.804097437s
Average: 11.29s
Agent Mode:
Min: 17.623815548s
Max: 39.572749400s
Average: 23.81s
Difference:
+12.52s (110.0% slower)
All timings:
Direct: 10.876837870 17.804097437 8.637378803 8.992257018 10.862649786 16.975990972 10.566292161 9.204778077 10.518423250 8.508621442
Agent: 19.436035538 17.623815548 31.055687961 22.744690925 22.402612281 20.129163521 19.148300195 26.634274552 39.572749400 19.353856522Thats it! Fun experiment that I wanted to talk about and share data on. Hopefully you learned something, and if you have other ideas for how we might make some improvements here, please let us know on GitHub!