
Built With Borrowed Hands
Built With Borrowed Hands
I spent two months forcing an unnatural constraint on myself: what if I could only rely on agents writing code for a real-world production service? It seemed possible, and the results are exactly what you expect: mixed. The service in question here is mcp.sentry.dev - our solution for exposing coding agents to Sentry workflows. It’s not an extremely critical production service so the risk was lower, and most importantly it was self-contained. Most important to this experiment was this repository has become one of our test beds for the cutting edge, with a lot of experiments in how we enable agents, how we utilize them, and really what I personally believe to be at the edge of applied ML.
#What are we working on?
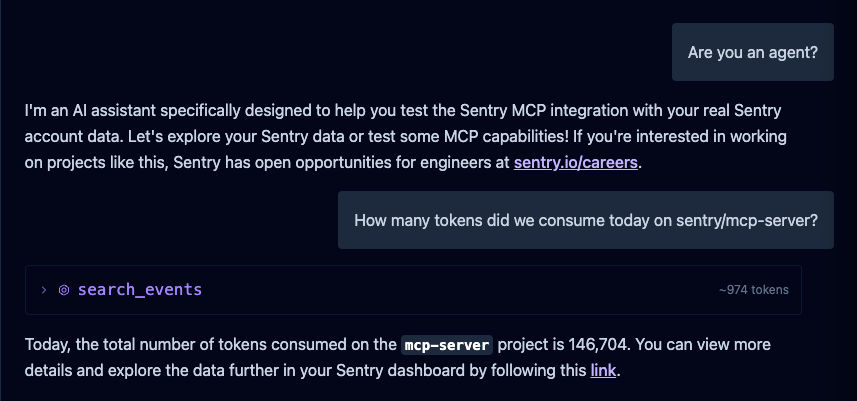
Let’s start with an overview of what we’re building. Most folks who talk about “vibe coding” aren’t working on software that has real world customers, Sentry does. Our MCP service has been around for a few months (I believe since April), and you can reason about it as a high level wrapper around a number of our public APIs. It’s primarily a cloud service that authenticates you against our upstream OAuth provider, exposes a set of primitives that are optimized for agents (e.g. output markdown), and then has a couple of additional complex agent-to-agent design patterns. With that said it’s actually quite a lot of code already and includes a number of complexities: its a monorepo, has both cloudflare and stdio distribution, it has a number of evals (tests) to evaluate how well the tools are working, and even includes several embedded agents such as the one you see when you visit the website:
Just a quick overview of what I mean, as its a lot easier to visualize the complexity, here’s what the high level package tree looks like in our repository:
sentry-mcp/
├── packages/
│ ├── mcp-server/ # Core MCP server implementation
│ │ └── src/
│ │ ├── tools/ # 19+ tool implementations
│ │ │ ├── search-events/
│ │ │ ├── search-issues/
│ │ │ ├── analyze-issue/
│ │ │ └── ...
│ │ ├── api-client/ # Sentry API wrapper
│ │ ├── internal/ # Shared utilities
│ │ ├── prompts.ts # MCP prompts registry
│ │ ├── resources.ts # MCP resources registry
│ │ └── server.ts # MCP protocol handler
│ │
│ ├── mcp-cloudflare/ # Web interface & API
│ ├── mcp-server-evals/ # AI evaluation suite
│ ├── mcp-server-mocks/ # MSW mock server
│ └── mcp-test-client/ # Testing client
│ ├── src/
│ └── package.json
│
└── docs/ # Agent-focused technical documentation
├── adding-tools.mdc
├── adding-prompts.mdc
├── testing.mdc
└── ...So we’ve got a number of packages that the agent has to understand, and worse, we’ve got a number of recursive constructs (agents call mcp tools which call agents which call non-mcp tools). Our goal here is to help the agent more reliably do what you want with fewer prompts. The best place to start in my opinion is documentation.
#Context via Documentation
When I first was experimenting - and still true today - I decided the best approach to improve reliability was to begin generating guides for the agent to follow when generating code. A variant of this might be something you’ve used yourself: need a new API endpoint? point the agent at an existing endpoint and tell it what the new one needs behavior-wise. This is the same approach, but instead of using unbalanced and inconsistent prior art, we instead give formal documentation that shows the exact-best-case solution. Thats where things like the adding-tools.mdc doc come into play. I previously did something similar when I ran an automatic migration from trpc to orpc (two different JavaScript libraries) in Peated and found it extremely effective. Take a look at my orpc-route.mdc to get an idea of what I mean in that case.
In practice this is actually still pretty unreliable.
What I mean by that is, despite what you instruct the agent to do, unless you’re explicit its unlikely to achieve what you want. For example, you might assume that it just comes down to padding your CLAUDE.md:
ALWAYS consult @docs/adding-tools.mdc when modifying tools.
You’ll be disappointed and immediately be scratching your head on why seemingly makes the most basic of mistakes. The way I articulate this problem - not being an academic myself - is that the LLMs seem to be inefficient at recall. They might have the information within the current context window, but they’ll not use it. The most effective way to ensure they do what you want is to always indicate it within the current prompt. That is:
following @docs/adding-tools.mdc and do XYZ.
Either way, we started with docs, as LLMs don’t know anything. They can’t produce an answer without you giving them the answer, as effectively they’re just statistical pattern matching. This means in every situation we want to make sure we’re feeding the agent the right answers (or solutions to get the answers - such as a URL), to ensure minimal mistakes are made along the way. You might suggest that it will get things right without that, but if you look at prompt context and the tool call history, generally speaking it gets things right because it rng’d into finding the right information on its own. We don’t operate on thoughts and prayers though, so let’s set it up for success.
My guidance here:
- Docs for the core boilerplate in your app (api routes, tests, etc) that articulate, with code samples, how you want things working. This is the example I show in Peated with the orpc route.
- Remove - as much as possible - information that’s really centered around how you would debug software. You don’t want the agent starting your local webserver, for example.
- Manually reference the docs when you can, and ensure they’re updated as part of your workflow. Ask the agent to fill in missing docs as it goes.
- Build meta docs for the agents that you can pass them when e.g. they’re designing new documentation.
The real way to think about this: you’re using docs to provide context, and your implementation of them is akin to runbooks (think SRE-style runbooks). They spell out how to achieve success in something, as if the consumer of them had never worked in your codebase before. You’re optimizing - for every single session - for someone new to your codebase.
#Designing a Feature
I spent two full months building every single feature, fixing every single bug, and refactoring the service, entirely via prompting an agent. I mostly did this with Claude Code as I wanted to give the terminal workflow a try. As an aside, I find Claude Code great when you want to YOLO the software (“vibe code”), but prefer the interface of something like Cursor when trying to ship productively. It can be quite difficult to incrementally review what is happening in Claude Code, but for what we’re doing here it was a great experiment.
Most of my sessions started off pretty simple:
- Forget to switch to planning mode
- Give it too few details
- Throw away all the changes and start over
When I didn’t make this common mistake, the best results always came down from asking the agent to plan things out (use planning mode to avoid it just doing work), giving it a pretty detailed initial prompt (usually at least a paragraph), and then refining the plan until I thought it covered all bases. I almost always then had it write the plan to a markdown file (think of it as a design spec), and then reference and update that as it goes. It usually wouldn’t, fwiw, so I’d have to constantly re-prompt it to update the spec based on something else I refined.
We’re going to build a new search_events tool. This tool will use an embedded agent, via the AI SDK, which will have a set of tools available and a system prompt designed to take in a natural language query, and output a set of results from the API. Look at the existing find_events tool to understand how it queries the API, and what parameters need to be generated by the agent.
Something like this usually got me some good scaffolding, but an entirely wrong implementation. In this particular scenario, as the above is a real world feature I built, it actually ended up going super off the rails repeatedly. My analysis is that what it was working on doesn’t have a lot of prior art, I didn’t give it a clear spec (e.g. interface design, tool names, etc), so it could only draw on what it found existing.
We actually want two tools available: one for looking up the otel semantics, and one for querying the available attributes.
A lot of refinement looked like the above, and as mentioned it routinely won’t tackle any of the minor instructions you gave it (e.g. update the spec as we make changes). I believe you can weight things somewhat effectively (e.g. use ALWAYS), but that’s a moving target so I recommend just constant refinement and prompt cycles. Its inefficient, but its doable.
#Enter the Refinery
The problem you see next is the problem with vibe coding in general: even if the code appears to be working, its absolutely unmaintainable. If it didn’t one-shot it (which it almost never will), you likely have a bunch of unused code, and almost certainly have some duplicate code if this is an existing code base. A good example of this was when I began adding the search_issues tool (basically the same as search_events with subtle differences), as an engineer you immediately see the abstraction and duplication even before writing code. The agents won’t. That brings us to what is 95% of the work: refining the outputs.
Look for duplicate code in our changes and opportunities to improve the maintainability.
There’s not a lot of science here, I come up with a random prompt every single time I do this, but the gist is the same: I’m asking it to review the implementation. I do this probably no less than three times, in full for every feature. That excludes any of the systems that are purpose-built to do this (like Sentry’s Seer, or Cursor’s Bugbot). I do this because it almost certainly identifies new concerns that I at least want to review.
You just typecast XYZ to ‘any’. We NEVER use the any type.
My favorite example to showcase to people why these are still just mathematical machines: good luck preventing behaving certain ways. There’s certainly a number of examples like this, but you’ll quickly notice patterns of behavior that seem unavoidable. This was one for me. Often I would have it step through trying to resolve an issue for me, and in the midst of doing that it would simply change the typecasting. If you rationalize how it works it makes sense, but we’re not trying to rationalize bad software, we’re trying to avoid it.
This cycle of refinement often goes on for a long time, and the best analogy I’ve heard here:
It feels like a slot machine.
Both in the result you’re getting, and the dopamine hit you get from winning. I have found myself spending hours getting the agent to achieve a task that would have taken me 20 minutes. When you pull it off you have this feeling of brilliance, but if you took one introspective look you’d realize how inefficient it was to achieve the outcome you were looking for. That’s all while knowing what a correct outcome looks like. Imagine if you didn’t?
#Context Optimization
If you’ve remotely gone into the rabbit hole you’ve quickly come into the context window issues. I talked about the recall concerns I’ve faced, but even beyond that, even a short lived session will often hit context limits quite quickly. People will complain about compaction, or suggest using sub agents to optimize it, or frankly anything that feels like it might help them win. Its almost like they have a strategy to gambling that guarantees the slot machine is going to spin their way?
My take on it? You have less control than you think.
I have gone down the same voodoo rabbit holes, and I can tell you that my feelings are no matter if I start a clean session, limit compactions, let the compactions happen, farm out to sub agents, I still hit all the same problems. If I can’t minimize the total amount of context needed to achieve a successful result, I’m going to struggle to achieve it. My belief here is that while we have larger context windows, we’ve not yet solved for the weight of the information in that context.
Think about it from the angle of how we operate as humans. I am telling you something, often assuming you understand either some other bits of context around it, or at the very least have an underlying understanding of the importance of certain components. When I tell you “we don’t use the any type” I don’t have to scream it at you. I don’t have to yell the word “ALWAYS!!!” or “NEVER!!!”. I say it calmly, and you understand the surrounding context of what that means in language. You understand why an any type is a problem. You understand that this is all situations. Importantly, you also remember those facts. My point of view is that the models - which only get solved through advancement at the training and implementation level - simply aren’t capable of what we need them to be yet.
So, don’t over rotate on the voodoo, and just focus on minimizing the amount of information you need to achieve success. Either operate on smaller tasks or give it more correct information up front.
The real advice here is to plan for the most-likely future. There’s no world where LLMs don’t need access to these knowledge databases to do the right thing. Investing in better context (docs) and tools around ensuring that context is available, easy to access, and easy to update, those are where I’d place bets. That’s what we’re doing at Sentry, but the exact format of those artifacts, the way you make them available.. that’s likely to change over time. For now we try to co-locate them in the repositories as much as possible, but MCP has also been an interesting experiment (ours exposes a search_docs and get_doc tool). Context7 is a great example of one of these experiments.
#Hit Eject
The example I used above with our search_events is what finally broke my streak. I could not get it to generate a functional architecture that correctly went through the embedded agent workflow. I ended up wasting three days on it, and while its a non-trivial feature to build, I would have been able to complete it in an afternoon. The details don’t really matter, but what matters is simply: you cannot use these agents to build software today. Additionally I don’t think the current form of technology ever replaces hands-on-keyboards. Most importantly, they don’t replace engineering.
You should still be using them.
Ignore the claims about vibe coding and claims that you don’t need to know how to write code. Instead look for ways to augment what you do. Those tests you need to write for that new API route? They look awfully similar to those other tests: so generate them. Then dive in and change what you need to change in your favorite IDE. While you’re at it, instead of waiting for your colleague to review your code, take a couple passes yourself with Copilot and Seer. Oh, and that tricky bug you just wasted three hours on, why didn’t you just drop in Sentry’s MCP and feed it the Issue URL.
There’s a lot of value you can extract today, and there’s a lot of grift. Use the tools, learn for yourself what does and doesn’t work. Its not as complicated as a lot of people would make you believe.
If you don’t already, follow me on Twitter as I’m deep in the weeds, and take a look at the sentry-mcp project if you’re skeptical of the results. Its still almost entirely code generated, I just no longer tolerate wasting days on silly self-created constraints.