
Skill Synthesis
Skill Synthesis
Recently we discovered a few fairly trivial IDORs in Sentry. This led me to immediately demand why we’re not trying to prevent these using LLMs. They’re pretty damn good at this kind of thing, and we have virtually unlimited budget. Why aren’t we having an agent make sure we never introduce another IDOR?
There was no reason, other than we hadn’t done the work. So I did, and I built Warden.
I didn’t stop at security vulns though, I imagined it a little differently. What if we could take the Skill packaging and use it as the context to feed into our harness, giving us a generalizable code review agent. That’s what I did.
Skills work really well for this because they include a few key components:
- SKILL.md is really your core system prompt (we extend Claude Code with it)
- references/ give you a great way to feed in additional context on-demand
- scripts/ are, while not great, a reasonable proxy for tools
We took all of that, wrapped it in a harness that integrated well with both GitHub and a local CLI, and allowed you to load any skill in it. It worked!
Except it didn’t detect any security vulnerabilities yet. To do that we’d need to develop a skill. We have to point the LLM at the right kinds of information to make sure it’s going to reliably detect the concerns. This was harder than I thought.
My thinking around this was pretty simple:
- Start with a skill helper:
/skill-creatorwould generate proper skills for us. - Take a collection of trustworthy source information, have Claude Code suck all that in and generate a new skill.
Note: This is what I call Skill Synthesis, and it’s how I build all skills currently.
So I took the OWASP Cheat Sheets, plugged it into Claude Code, and it output a generalized /security-review skill. It was fine, but it was flagging a lot of false positives, and missing some clear Django ORM mishaps.
“How would we make the synthesis more reliable?” was my first question. What if we used real world data, from our own application? Sentry’s not a new project, and we’ve had plenty of security patches over the last 15 years. Hell, we’ve had plenty in the last year. What if we took everything that looked like a security patch and fed that into the skill as its context?
Take a look at the last year’s worth of commits in this repository. Look for anything that resembles a security fix. Collect all of those commits, and create a set of patterns to identify future security vulnerabilities. Those patterns will become a new skill, which you should build using /skill-writer.
(this is not exactly the prompt, but it illustrates the idea)
You can see a form of that output in Sentry as the /sentry-security skill.
That first synthesis wasn’t enough though, and I wanted to talk about this because folks don’t understand both how easy it is, but also that it requires some actual effort to get good results.
From here I plugged that skill into Warden and I ran it locally:
$ warden "**/*.py" --skill sentry-security
__ __ _
/ / /\ \ \__ _ _ __ __| | ___ _ __
\ \/ \/ / _` | '__/ _` |/ _ \ '_ \
\ /\ / (_| | | | (_| | __/ | | |
\/ \/ \__,_|_| \__,_|\___|_| |_|
v0.14.0
→ Building context from files...
✓ Found 7551 files
FILES 7551 files · 7551 chunks
+ bin/__init__.py (1 chunk)
+ bin/extension_language_map.py (1 chunk)
+ bin/react-to-product-owners-yml-changes.py (1 chunk)
+ bin/send_metrics.py (1 chunk)
+ devenv/post_fetch.py (1 chunk)
+ devenv/sync.py (1 chunk)
+ fixtures/__init__.py (1 chunk)
+ fixtures/apidocs_test_case.py (1 chunk)
+ fixtures/bitbucket.py (1 chunk)
+ fixtures/bitbucket_server.py (1 chunk)
... and 7541 more
⠧ sentry-security [0/4429 files]
⠧ src/sentry/__init__.py [1/1]
⠧ src/sentry/__main__.py [1/1]
⠧ src/sentry/adoption/__init__.py [1/1]
⠧ src/sentry/adoption/manager.py [1/1]It came back with.. let’s just say a few false positives (ok a lot). You’d assume it didn’t work, but that’s only because we hadn’t refined the skill yet. This is software at the end of the day, and software requires iteration.
I took the entirety of the results, and I plugged them into two more prompts:
-
A session intended to improve the
/sentry-securityskill. I asked it to determine the validity of the results, figure out what we’d change in our skill to reduce false positives, and fed it back through/skill-creator. -
On the Warden front, I did a similar exercise. Focusing its prompt on ensuring it understood it could only control the core harness, and what we should improve there.
The Warden side identified some clear macro improvements (ones you’d typically find in “context engineering” guidance), and the Sentry side broadened and tightened various guidelines.
I then ran it again. This is the meta optimization loop that you need to repeat to improve the accuracy. It’s not all that different from using something like Evals at the end of the day.
After two passes at this we had something that was reliable-enough. We ran it on a chunk of the codebase and it came back with 17 findings.
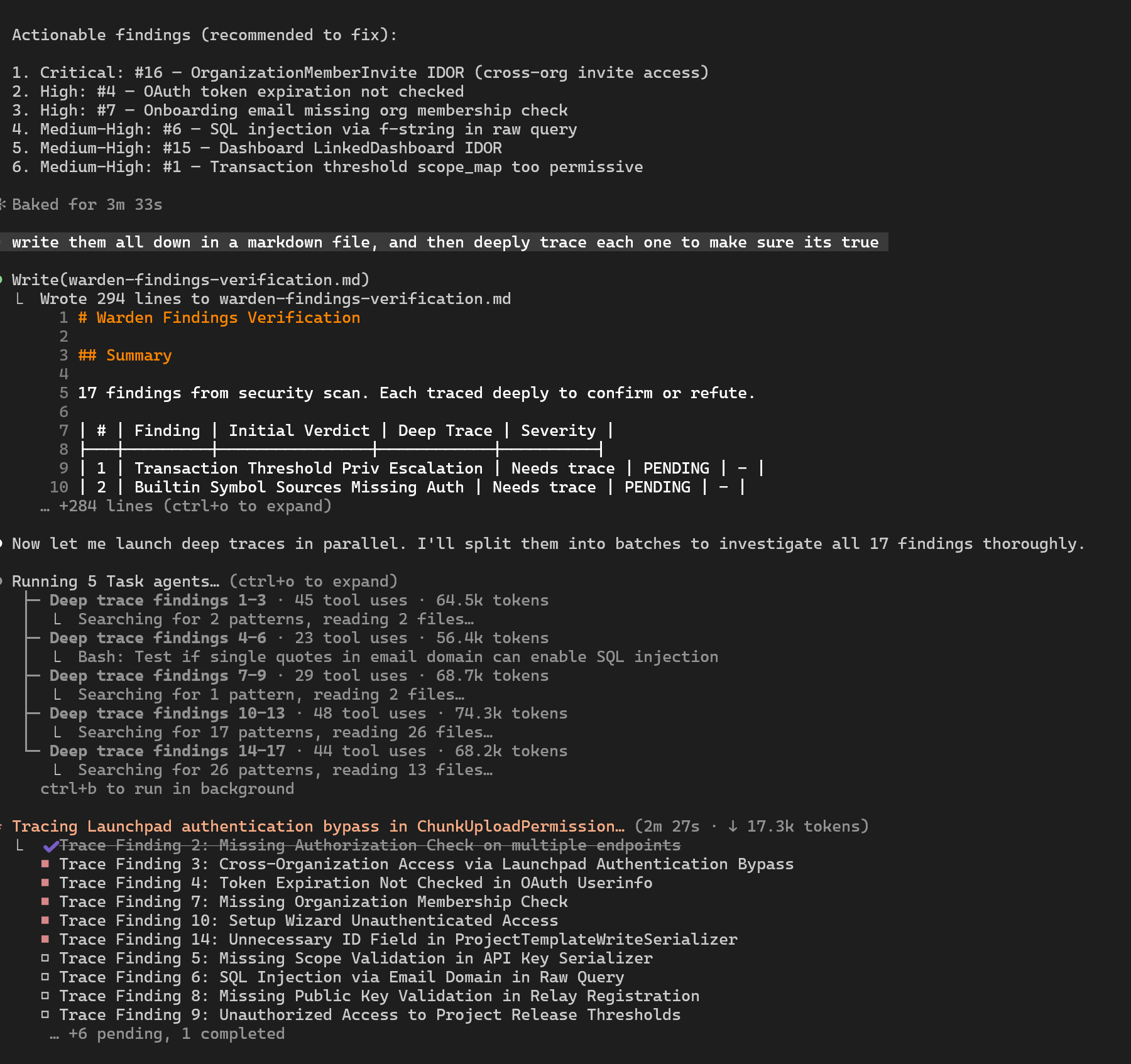
We disqualified half of those, and had 8 valid security vulnerabilities. None of them were wide scoped, and some were more along the lines of defense-in-depth, but all valid.
This was accomplished, end-to-end, in a single work day. Granted Warden had a few weeks into its development, but it had no security-specific behaviors in its harness. These vulnerabilities on the other hand had gone undetected, in some cases, for years. Think about that. We pay pen testers regularly, we have an active bounty program, we do code review and follow most best practices.
The real surprise wasn’t that it worked. It was how well synthesis dialed in the accuracy. Feeding the LLM our own commit history, our own past mistakes, gave it something generic security guidance never could: context for our codebase, our abstractions, our patterns. It won’t always be this clean, but the technique is sound.
Skills are just files in a repo. That means you get version control, code review, diffs, all the standard practices we already use for software. They’re a great way to package up repeatable workflows and domain knowledge into something that’s iterable and shareable.
We use this same synthesis approach to build skills across the board now. /commit and /create-pr were both synthesized from our developer documentation. /brand-guidelines from our, well, brand guidelines. /iterate-pr was transcribed from real world scenarios, and then improved by feeding its own failure cases back through synthesis. The technique is the same every time: take trustworthy source material, feed it through a skill creator, iterate on the output until it’s accurate.
The current agenda is to see if we can push this further with Sentry’s production data. Could we improve error prediction? Predict performance bottlenecks? We’ll see.
If you’re curious, or idk like videos instead of text, I published a short-ish walkthrough of this (from that same day) on YouTube. We’ve also published a bunch of our generic development skills at getsentry/skills.
p.s. Warden is Fair Source licensed and I’d love to hear how it works for you!