
Running Evals in Vitest
Running Evals in Vitest
I have been fiddling with an MCP server for Sentry over the last few weeks. It’s been a fun project to explore exposing Sentry’s interactions within an LLM’s context - particularly useful in clients like Cursor or VSCode. As part of setting this up I went down a rabbit hole of my standard checkboxes for a software stack, and got hung up a bit on testing capabilities. There wasn’t an obvious great way to use vitest with Evals.
You’re probably asking “What are Evals?!” right now, so lets start there.
Generally speaking when you test your code, you’re testing a pretty specific set of inputs and outputs. When building against an LLM you need something similar, but its much more about intent and qualitative analysis than it is pure correctness. That is, I can’t assert that when I stuff a prompt into an LLM that I get a precise output, as there’s variability and the models are always changing. Instead, we follow a practice where we run evaluations - scenarios designed to verify that your inputs qualitatively achieve your desired outcome.
For example, instead of assert add(1, 1) === 2, we define a scenario:
const input = "What is the capital of France?";
const answer = "Paris";This input then gets passed into your implementation combined with your system prompt, tools, and whatever other behavior you defined. It then takes the output and runs that against an evaluation, for example an LLM-as-a-judge scenario. A simplified version of an evaluation for the above:
You are comparing a submitted answer to an expert answer on a given question.
[BEGIN DATA]
************
[Question]: ${input}
************
[Expert]: ${expectedAnswer}
************
[Submission]: ${generatedAnswer}
************
[END DATA]
Compare the factual content of the submitted answer with the expert answer. Ignore any differences in style, grammar, or punctuation.The idea here is that you’re going to pass your evaluation into another LLM and have it judge the answer. In some cases you may even pass it into multiple different models and look at the aggregate, to understand if you’re statistically improving. If you squint, you’ll notice we’re just testing, but with a new set of primitives.
To understand what I mean, imagine the following:
async function get_error(id) {
const data = await fetch(...).json();
return `# ${data.description}`
}And now if we changed that to this new markdown output:
async function get_error(id) {
const data = await fetch(...).json();
return `# Error Details\nType: ${data.type}\nValue: ${data.value}`
}That could have unknown consequences on its use in the upstream clients. The models could interpret the markdown in a wildly different way. While we can’t control all of that, we at least want to test for common scenarios to ensure that the API we’re building has some level of predictability around it. In our case we do that by writing an eval that would trigger the tool call and then assert that the response is approximately what we expect.
I wanted to wire up evals to our test suite which runs within GitHub Actions. I wanted a traditional CI-based workflow that ensured any changes to qualitative components would verify that the scenarios we defined worked at least as well as before. This was a bit more difficult than I hoped as just about everything is coupled to some third party service, frankly for no reason at all. I discovered Evalite pretty quickly and it looked like a great solution. It was almost there for me, but I wanted native vitest compatibility (vs something simply using vitest as a framework). So I built vitest-evals.
vitest-evals takes the same approach to evals as Evalite and the big cloud vendors do, but it does it with a test-first approach. Right now, it’s pretty bare bones, but importantly it lets you:
- Define your evals in the same fashion as other frameworks
- Run them as part of your traditional test suite (or not, via a different
vitest.config.ts) - Report them within your favorite tools (e.g. codecov and junit compatible reporting)
The reporting is the critical part here - we wanted this in our CI process. While there’s a lot more we can do here, below you can see it integrated into Codecov with near zero effort:
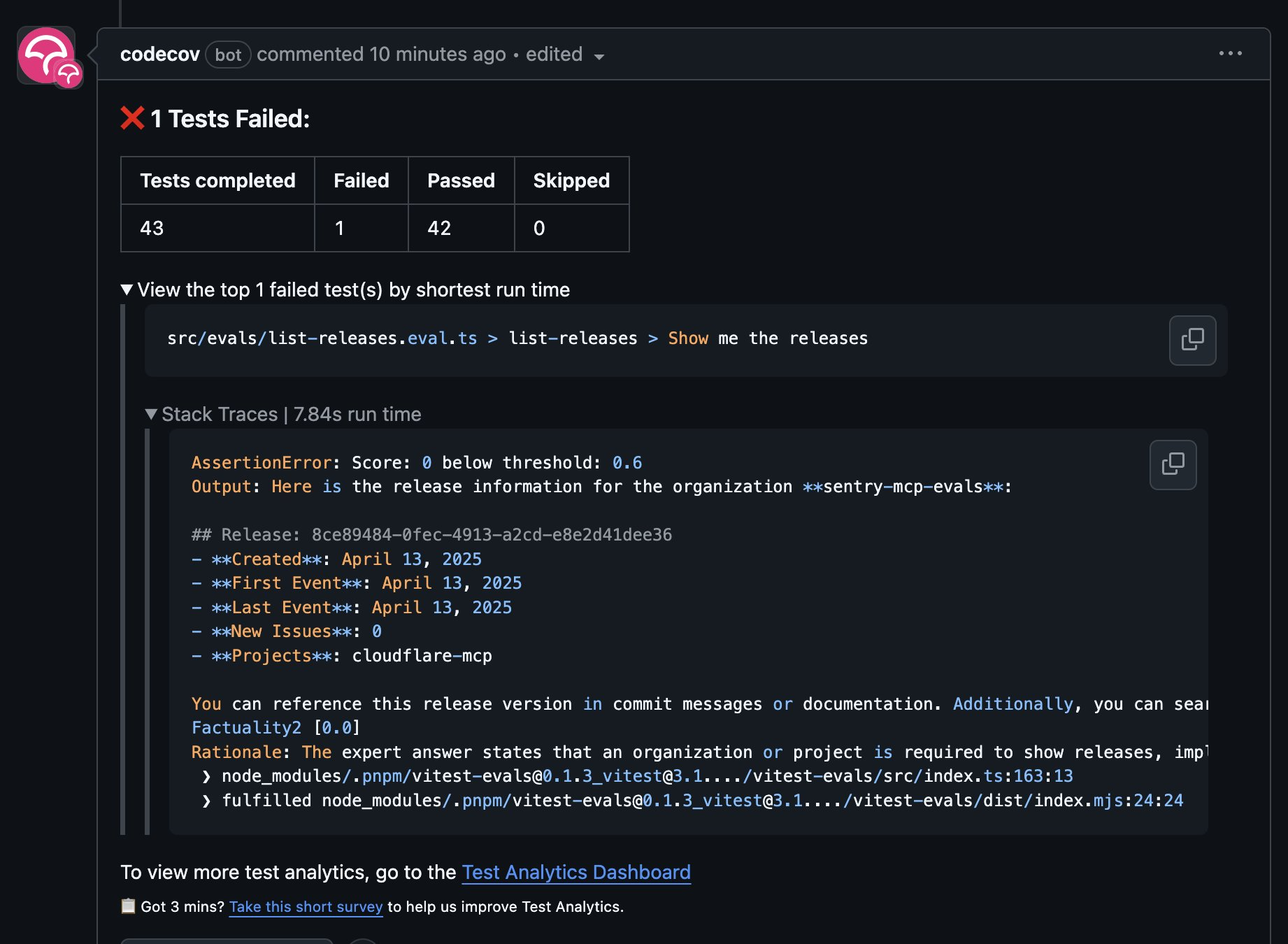
There’s not much more to add than that, but here’s an example, using a Factuality scorer similar to the example we showed above:
import { describeEval } from "vitest-evals";
import { Factuality } from "autoevals";
import { openai } from "@ai-sdk/openai";
import { generateText } from "ai";
describeEval("capitals", {
data: async () => {
return [
{
input: "What is the capital of France?",
expected: "Paris",
},
];
},
task: async (prompt: string) => {
const model = openai("gpt-4o");
const { text } = await generateText({
model,
prompt,
})
return text;
},
// Scorers determine if the response was acceptable - in this case we're using
// a secondary LLM prompt to judge the response of the first.
scorers: [Factuality],
// The threshold required for the average score for this eval to pass. This will be
// based on the scorers you've provided, and in the case of Factuality, we might be
// ok with a 60% score (see the implementation for why).
threshold: 0.6,
})Take a look at vitest-evals for more details, and if you want to see it in action, I’ve wired it up to our MCP project (sentry-mcp).